Today we’re announcing the Farama Foundation – a new nonprofit organization designed in part to house major existing open source reinforcement learning (“RL”) libraries in a neutral nonprofit body. We aim to provide standardization and long term maintenance to these projects, as well as improvements to their reproducibility, performance, and quality of life features. We are also working to develop key pieces of missing software for the open source reinforcement learning ecosystem.
Our mission is to develop and maintain open source reinforcement learning tools, making reinforcement learning research faster and more productive, and reducing the engineering workload required to apply RL in both research and industry.
This post explains who we are, what we’re working on right now, and what our long term goals and vision are. This post also publicly announces the release of Gymnasium, a library where the future maintenance of OpenAI Gym will be taking place.
Reinforcement Learning Tooling and Environments
Reinforcement learning is a popular approach to AI where an agent learns to take sequential actions in an environment through trial and error. In practice, environments are most often a piece of software like a game or simulation, but the real world works too. Reinforcement learning has been able to achieve human level performance, or better, in a wide variety of tasks such as controlling robots, playing games, or automating industrial processes. Reinforcement learning has also been responsible for some of the greatest achievements of AI in recent history, such as AlphaGo, AlphaStar, and DOTA2.
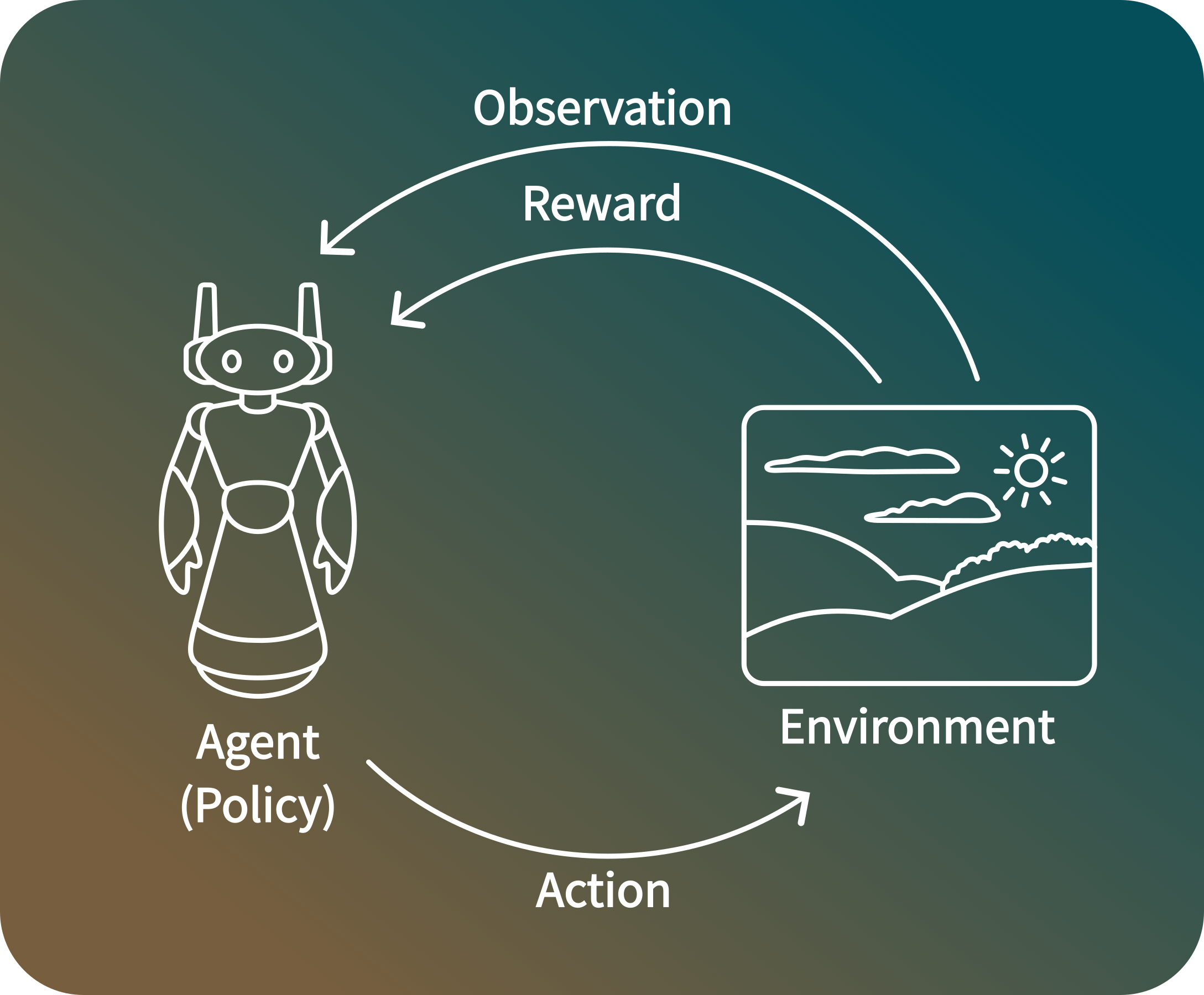
Reinforcement learning is conceptualized as a loop where the agent observes the state of its environment, and then takes an action that alters that state. At the time of receiving the next observation, the agent also receives a reward associated with the most recent action. This process continues in a cycle, and during learning the agent seeks to maximize its expected average reward . Here’s a visualization of this cycle:
In supervised learning, the basic software stack typically only has three components: the dataset, preprocessing of the dataset, and the deep learning library. In reinforcement learning, the software stack is much more complex. It starts with constructing the environment itself, usually a piece of software like a simulation or a video game. The base environment logic is then wrapped with an API that learning code can be applied to.
Depending on how the reinforcement learning algorithm interacts with the environment, preprocessing wrappers are then applied (e.g. to make image observations greyscale). Only after all of this is done can a reinforcement learning algorithm be applied, which are typically implemented using deep learning tools (e.g. PyTorch, TensorFlow, Jax). A comparison of both software stacks is shown in the simplest form below:
Supervised Learning Stack
Deep Learning Library
(e.g. PyTorch or TensorFlow)
Preprocessing
Dataset
(e.g. labeled images)
Reinforcement Learning Stack
Deep Learning Library
(e.g. PyTorch or TensorFlow)
RL Algorithm
Preprocessing Wrappers
Environment Wrapper
(Standard Interface)
Environment
(e.g. Robotics Simulation, Video Game, etc.)
The Environment Problem for Researchers
Reinforcement learning’s reliance on standard software environments as opposed to datasets creates a lot of unique problems for the field. Given a piece of image classification code, you can give any sufficiently large labeled image dataset to it, press run, and it will mostly work. Unlike datasets, when you’re dealing with software based environments like games, you have to make sure the environment runs on your operating system and CPU architecture, is bug-free, runs with modern versions of the underlying tools (e.g. a current version of Python), and has an API that is compatible with your learning code. You’d also like it to have documentation, be available for installation via package manager, and have specialized reproducibility features.
Previously, RL environment projects have been maintained and owned on GitHub by separate groups or individuals. This means that if someone suddenly quits, burns out or gets hit by a bus, or a company goes under, maintenance completely stops. Even the standard open source approach of someone forking the environment is undesirable here, because everyone needs to use the exact same version of an environment for reproducibility and consistency across the research field.
Beyond the quality of life, reproducibility, and productivity issues this creates for researchers, the reality is that as long as the field of reinforcement learning exists, standard maintained environments that can allow for performance comparisons are needed. Our long term solution to this problem is to have the repositories be managed by a unified neutral nonprofit organization, akin to the Linux Foundation or Apache Software Foundation, that maintains the libraries over time and brings them into compliance with a unified and consistent set of standards. This is a large part of what Farama was created to accomplish.
The Standard API Problem and The Origins of The Farama Foundation
In order to have standardized environments and modular RL code in general, there needs to be a well-designed and easy to use standard API for accessing reinforcement learning environments. For most use cases, this already exists through a Python library called Gym. Gym was originally created by OpenAI 6 years ago, and it includes a standard API, tools to make environments comply with that API, and a set of assorted reference environments that have become very widely used benchmarks. It’s been installed more than 43 million times via pip, cited more than 4,500 times on Google Scholar, and is used by more than 32,000 projects on GitHub. This makes it by far the most used RL library in the world.
The Farama Foundation effectively began with the development of PettingZoo, which is basically Gym for multi-agent environments. PettingZoo was developed over the course of a year by 13 contributors. Amongst other things, its development involved the standardization or creation of about 60 environments, including adding support to the ALE for multi-player Atari games for the first time. PettingZoo was released in late 2020 and is now used widely, with 850,000 installations via pip, making it the third most installed RL library in the world.
Gym did a lot of things very well, but OpenAI didn’t devote substantial resources to it beyond its initial release. The maintenance of Gym gradually decreased until Gym became wholly unmaintained in late 2020. In early 2021, OpenAI gave us control over the Gym repository.
Since then, much more development has occurred than in the previous 5 years following its release. Our updates to Gym included changing the core API to resolve long standing issues with the design (a blog post on this is coming soon), creating a full-fledged documentation website for the first time ever, adding a compliance checker for the API, fixing massive bugs across every surface of the code base (when we took over, even installation didn’t work correctly in many cases), removing several dependencies on long deprecated software, and much more.
The core team of contributors maintaining Gym and PettingZoo dramatically grew into a massive international team, and our greater group of contributors, now known as the Farama Foundation, currently spans 14 timezones. Having standard APIs like Gym and PettingZoo be well-maintained and stabilized in a neutral nonprofit body is very important for the field, and is a prerequisite for standardizing environment libraries.
Gymnasium
This brings us to Gymnasium. It’s essentially just our fork of Gym that will be maintained going forward. It can be trivially dropped into any existing code base by replacing import gym with import gymnasium as gym, and Gymnasium 0.26.2 is otherwise the same as Gym 0.26.2.
Even for the largest projects, upgrading is trivial as long as they’re up-to-date with the latest version of Gym. We’re doing this so that the API an entire field depends on can be maintained in a neutral entity long term, and to give us access to additional permissions so we can have a more productive and sustainable development and release workflow. It’s our understanding that OpenAI has no plans to develop Gym going forward, so this won’t create a situation where the community becomes divided by two competing libraries.
Right now, Gymnasium is live and you can install it with the usual pip install gymnasium. The documentation website is available here and we encourage users to begin upgrading (if you’re already on the newest version of Gym, this should be trivial). Many large projects have already agreed to upgrade to Gymnasium in the near future, such as CleanRL and Stable Baselines 3.
You can view the development roadmap for Gymnasium here, though it’s basically the same as before. We have no plans for further breaking changes to the core API, and we’ll mainly be focusing on upgrades to vectorized environments and reimplementing all the built-in environments in Gymnasium to be able to run on accelerator hardware like GPUs, changes which represent a potential environment speed up of 10x and 1000x respectively. We hope these changes will make reinforcement learning much more accessible in education and allow for researchers to experiment with new ideas much faster.
Our Other Environments
Beyond PettingZoo and Gymnasium, we’ve already begun officially maintaining several other popular benchmark environments. These include MAgent2, D4RL, Minigrid (formerly gym-minigrid), Miniworld (formerly gym-miniworld), MiniWoB++ and MicroRTS/MicroRTS-Py (formerly gym-microrts). You can view these and all of our other projects on our projects page.
We’re also currently in discussions with a number of other popular open source reinforcement learning environment libraries about bringing them in, and thus far the discussions have been overwhelmingly positive. If you’re the owner of a widely-used piece of RL software that you think should be part of the Farama Foundation and haven’t already heard from us, please reach out to us at contact@farama.org.
Our goal is to offer long term maintenance, standardize environments and add key quality of life features. Some of the most important quality of life features we’re working to add are consistent detailed documentation websites (like the ones we created for Gymnasium, PettingZoo, Minigrid and Gymnasium-Robotics), easy installation, support for multiple architectures and operating systems, type hinting, docstrings, and improved rendering functionality. You can read our full list of standards here. We’ve been classifying our projects into two classes – “Mature” projects that comply with these standards, and “Incubating” projects that we’re still actively working to bring up to our standards.
These projects show that current algorithms clearly are capable of incredible feats. However, those projects all generally had teams with more than 15 specialized, highly technically skilled members. Similar projects in supervised machine learning require a fraction of the resources due to readily available and compatible tooling. This means that the barrier to reinforcement learning seeing widespread deployment is a tooling problem. Our long term vision is to solve it.
We believe it is critical for the field that the tools researchers use function well and have long term support. As the initial wave of cleaning up the key benchmark environments passes, we want to turn our focus to developing a set of standardized and widely applicable tools with the intention of making reinforcement learning as easy as supervised learning. We want to make tools that “just work.” If we succeed, this could result in automation for a profoundly greater scope of tasks than anything before, including manufacturing, household devices and robots, automating menial computer tasks, and medical devices like insulin pumps. Our grand vision for our work is to essentially make “RLOps” a thing the way that MLOps is, and make deploying RL feasible for small teams and students.
Our Future Projects
These are the projects we plan to work on in the pursuit of making RL require less developer labor to deploy into real world applications:
Work with video game developers to compile gameplay from real users into the largest offline RL dataset ever created, and publicly release it so that GPT-for-RL styled projects can be attempted. (If you’re a video game developer and are interested in working with us on this – jkterry@farama.org).
Create a standard offline RL dataset format and repository. Development on this has begun – see Minari – and it will be integrated into all environments we manage.
Create good C APIs and tools, so that RL can be more easily deployed in applications like embedded systems or robots.
Create a learning library that would hopefully be the first widely used library that “just works,” even in complex and real world applications, including support for distributed computing. This is by far the most ambitious task on this list and deserves its own blog post.
Contributing
If you are interested in contributing your time to working on projects with the Farama Foundation, we would love to have you. The general process is to join our discord server where we coordinate all development, post a message with your experience and what you’re looking to do, and our project managers will work with you to get you started.
Donations
Farama has accomplished everything we’ve described above with entirely volunteer contributions. We’re looking for donations to allow our key developers to become full time employees, especially our team members managing other contributors.
Full time staff would make the development and maintenance of our projects more sustainable, let us bring environments to a mature state faster, and give us the capacity to manage many more environments. It would also let us release important new features faster, like making all of the environments in Gymnasium hardware accelerated by default, and give us the manpower to pursue the majority of our future project goals, like a GPT-for-RL enabling dataset.
We’re a 501c3 nonprofit in the United States, so donations to us are tax deductible. We have various perks for individuals or companies who donate larger sums.
Our work will allow engineers and researchers in both industry and academia to be substantially more productive, make novel forms of automation feasible, and will dramatically lower the barrier to entry for students. If you want to see our vision realized, please donate to the future of AI.
Final Notes
More than anything, we want to thank our team and community of contributors. Without their immense amount of work and dedication over the past year, truly none of this would’ve been possible.
If you’d like to meet our team, we’re going to host an “office hour” session on Wednesday, October 26th at Noon US Eastern time in the voice channel over on our discord server. If you’d like to chat or ask any questions, please join us there. We’ll also be releasing another blog post in 1-2 months updating everyone on all the new changes coming.